
Offline functional applications require a different way of data management than traditional web design. The client must own a local portion of the data and have it ready at hand to serve the users need.
In the traditional model, there are a variety of strategies used in modern design that helps to alleviate some of the pain of poor or intermittent connectivity. These are often used to simply to improve the feel of the user interface, prefetching, caching data, and optimistic rendering. All of these are only modest changes to the traditional server to client model.
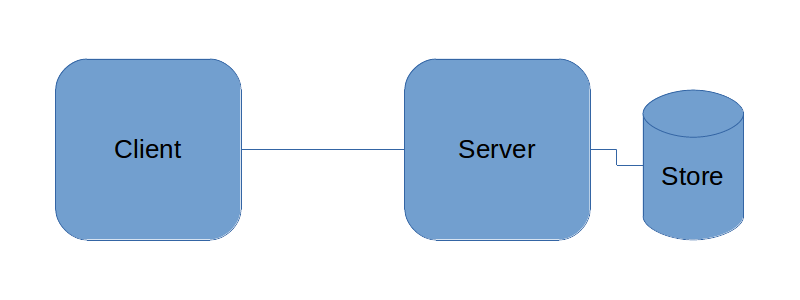
Some buffering systems are placed on the inputs and outputs of the client to ease the network requirement. But if we wish to produce an application that will function as a mobile app or PWA as a primary consideration where it is likely that there will be times with zero network connectivity this method does not work well. We might be able to turn our outbound buffer more permanent and that would help with some use cases. But often we still require that server data to do basic functionality within the app.
The minimum offline storage solution is to create a better store on the client to handle full offline use looks like this.
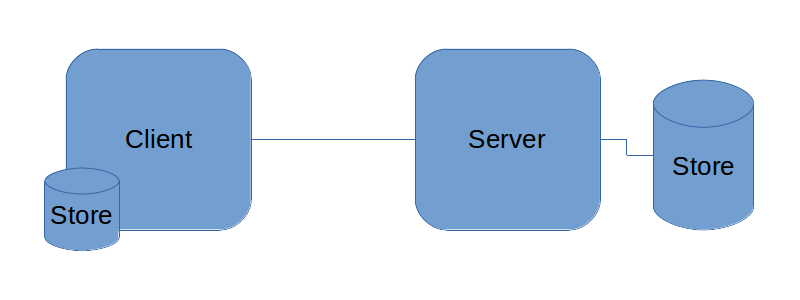
The picture looks relatively simple but there are some tricky parts. Not only are we adding a significant amount of complexity to the client with the additional data management. There needs to be a method or system to managed changes and updates between the two, or more, stores. There is a good possibility that there are conflicts arising between the different stores. Enter conflict-free replicated data types (CRDT). With such a system of change management in place, it allows us to manage all the stores both on multiple clients and a server. The stores will always have the ability to synchronize the data between them without unsolvable conflicts.
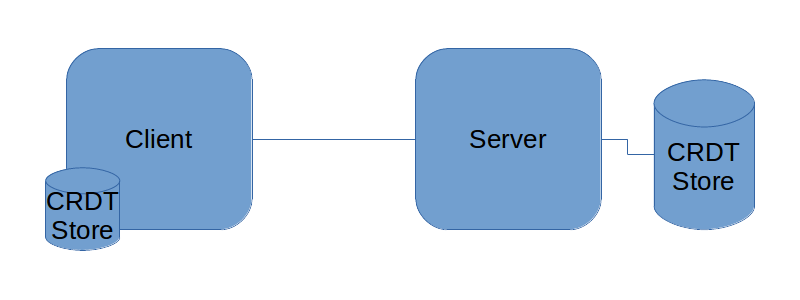
How does this work? Basically we are using change requests as a means of altering the other stores rather than copy or caching the stores themselves. When the client connects to the server, it doesn't download the whole store or some checksum of it. Instead, we ask for all the changes that have occurred to the store since our last update and then the client can also apply those same changes to it's store and then the client will have the same store as the server or vice versa. Changes can also be rewound and repatched if there is a necessary backdated change submitted by a client that hasn't connected in a while.
This is technology widely understood and used in the database world which makes it a perfect fit for this use case, tried and tested and now we can adapt it for user gratifying results in the offline use case.
This may seem like such a system that doesn't scale well into a large backend. It would be generally unacceptable for a client to need to download a 100MB database in order to operate. There has to be some kind of scale that the client operates at. This view of the data could be scoped to their personal data, like in the case of Apple's Notes app that uses CRDTs to synchronize between devices. Each user only has the data and changes relevant to their view and syncing only involved that data. In the case of other useful data that may not belong to the user, another possible discernible view into the data can be used. Recent threads the user has visited on a forum or social media system. Topics of interest to the user on a news feed.

